Pour moi, il est tout à fait normal que des lapins bleus soient enrhumés, qu'un extra-terrestre soit marié à une symphonie et qu'un petit caillou se sente bien dans la poche d'un enfant. L'enchaînement de tableaux entre une autruche qui danse et une sorcière en colère me semble parfaitement normal …
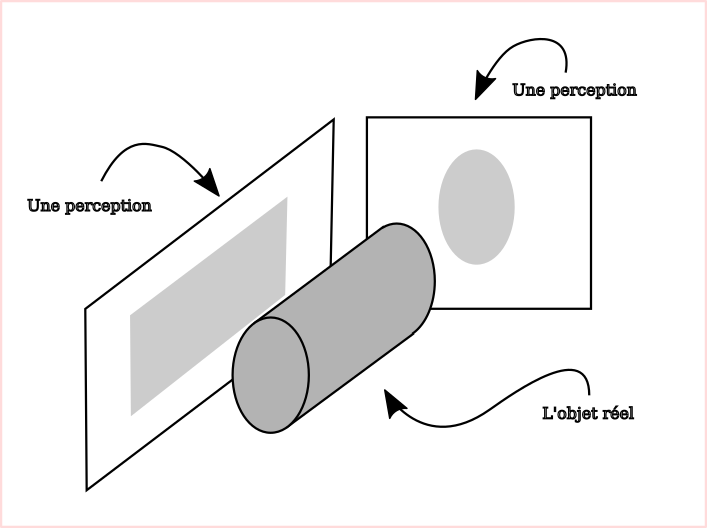
Peut-être avec-vous déjà vu l'illustration montrant un cylindre dont deux projections donnent un cercle d'une part et un rectangle d'autre part. Si ce n'est pas le cas, la voici ci-dessous :
Je ne me souviens plus réellement de la légende, je l'ai donc remise à ma manière, mais l'idée est là …
Il y a quelques années, je lisais un livre ancien sur le Forth, un langage assez particulier dans la famille des langages de programmation. L'auteur présentait un des avantages du Forth qui est que l'intégralité du langage et du système est accessible et modifiable par l'utilisateur. Dans sa lancée, il …
Dans les règles de programmation que j'ai pu croiser, il y a bien entendu le fameux « commentez votre code », dont je discutais les excès il y a 15 ans ici même. Une autre règle que j'ai pu croiser, et que je croise encore, c'est l'injonction à écire du code « explicite …
Après avoir été déçu par Choose Cthulhu livre 1,
j'ai enchaîné sur un autre livre jeu encore plus court. 52 chapitres, c'est peu, mais je me souviens de
petites histoires interactives dans des magazines (Jeux & Stratégies ?) qui étaient encore plus bref et
offrait pourtant une bonne expérience. Ou bien peut-être …
La dernière fois que j'ai parlé d'un livre jeu ici, c'était en 2009. Il y a un peu plus de 16 ans ! Et c'étaient en fait des mises à jour d'articles de 2005 et 2003...
J'avais commencé à ce moment à étudier la structure de quelques-uns des livres de la …
Hier, je discutais anecdotes de debug exotiques, et il m'est revenu celle-ci. Plus exactement, je ne l'ai jamais oubliée ; et pourtant,
l'histoire se situe en 1999, il y a donc un petit moment.
Je travaillais à ce moment-là sur un jeu Dreamcast. Le jeu était en fin de développement et …
Je me disais récemment que la plus grand compétence que j'ai pu apprendre dans ma vie, c'est la capacité
à dire « je ne sais pas ».
Ce n'est pas facile d'avouer que l'on ne sait pas quelque chose lorsqu'on est interrogé. On est interrogé
car, probablement, nous devrions savoir. Et le …
Récemment, on m'a prêté le livre « Le projet Unicorn », de Gene Kim. Gene Kim, pour moi, ce sont avant
tous les livres « Accelerate » et « The DevOps Handbook », dont il est co-auteur. Et donc la « mouvance »
DevOps.
Et c'est le thème de ce livre. Les bonnes pratiques de développement logiciel selon …
En août dernier, suite à une mise à jour de site, de PHP ou de je ne sais quoi d'autre, et en
naviguant sur des ressources du réseau gopher, j'avais pris une décision : passer tout le contenu
de ce site en mode static, tout comme je l'avais fait pour mon …